Despite the currently stifling hype surrounding artificial intelligence, AI has a long and storied history. I won’t waste time on this as I have already covered it in some detail in the past and there are surely way too many retrospective articles for me to attempt to fill in yet another one. For a more general introduction to machine learning and AI, at least those subjects that I found interesting I invite you to look at the introduction category. For the uninitiated however, I must add that the study of Machine Learning and Artificial Intelligence has been, in many ways, the story of building models of systems; systems that we care about, but which are either too complex or ones we have an imperfect understanding of. In short, for the most part, the study of ML and AI is the study of modelling reality to some degree of precision.
In the recent past, massive strides have been made by the research community focusing on singular mode models. At this time of writing, AI has already beaten human performance at a long list of tasks and the list keeps getting longer by the day. Machine vision tasks such as object detection, image segmentation, as well as conversion models – like text to speech and speech to text models – are some examples of singular mode systems.
Even the glorified chatbots called LLMs, that are currently all the rage, are in their purest form, singular in their modality. Some advanced versions can pickup sarcasm and infer the tone of voice. However these models have some very significant shortcomings. To mention a few, LLMs can only deal with textual information, are very prone to hallucinations and lack real-world understanding. Despite there being multiple ways of hacking in more functionality, such as chain of thought reasoning or adding RAG (Retrieval-augmented generation), these leave a lot to be desired and are in many ways limited by the singular medium.
Cue Multimodal Machine Learning (MML). MML in many ways is the difference between reading a book and reading a book that has pictures. The pictures help guide the reader’s imagination, while the text can add more depth to what could be happening behind the scenes. Let us not let the simplistic example limit our imagination, MML is similarly useful wherever two or more data mediums can be used to inform each other.
The Rise of Multimodal AI:
‘Jack of all trades master of none but still better than a master of one.’
While the term “multimodal modeling” may not have been coined until more recently, the underlying concepts and ideas have been explored for decades. Initial ideas around multi modal models revolved around producing a fully functioning brain, something that could emulate human understanding more completely. Having such a model could help us create a Super Intelligence, and despite our ineptitude, rule over it like drunken inbred royalty that has forgotten who they have sworn to serve… But I digress.
More recently, the reason we are seeing a sudden revival in interest around multimodal models is much more mundane. In 2020, a veritable who’s who of researchers from OpenAI published the paper Scaling Laws for Neural Language Models which in its conclusion states:
We have observed consistent scalings of language model log-likelihood loss with non-embedding parameter
count N, dataset size D, and optimized training computation Cmin, as encapsulated in Equations (1.5) and
(1.6). Conversely, we find very weak dependence on many architectural and optimization hyperparameters.
which, in layman’s terms means that what really matters when training a large language model, is it’s size. With the ability to train ever larger models you can, as the research indicates, predictably expect increased performance. To take things even further, given that a model is large enough, it’s architecture, hyperparameter tuning, and other facets that previously divided the research field into covens, where shown to have little effect. Any company with access to quasi limitless compute decided to use this little fact to their advantage. After all, the recipe now was quite simple. All one needed to do is find more training data, build a larger model, drain a small city’s worth of energy resources for a few months and hey presto a new state of the art model is born. For a short while, this was the case, even the relatively uninitiated could use this scaling law to provide ever increasing performance to their models.
As so often happens, with quick wins such as this one, they are short lived. There is only so much textual data available on the internet. The internet a limited resource? Let me explain. We humans like to talk about lots of stuff, and there are so many of us around that you will in general be able to find groups dedicated to ideas, stories, languages and all sorts of interesting things. To help our imagination let’s think of this as a box full of all the things any human has ever written about, we can call this box Textual Space. Now imagine if you will, a box full of all the images on the internet, and to make things even simpler, let’s also consider movies, which are after all many pictures set after each other to be in this same box. Image Space. It will quickly be apparent that both Textual and Image Spaces overlap quite significantly, however are not quite the same. A story about a puppy we had as a child has a different flavor to the worn picture we still have in our wallet. What is more, they will still contain different information even if the story is about what is happening in the image. This sparse overlap, also spoken of as noisy redundancy is what makes multimodal learning so promising. The overlap can be used to help tie the two sets of data together, while the remaining unique information and it’s qualities could help build a better model.
At this point we can start identifying some initial tradeoffs. While you get the largest amount of combined information when there is little to no overlap between the spaces this is also the place where there is the least amount of information tying things together. The opposite also holds, having largely similar information will be easier to train on, however will provide very little in the way of growing your model’s capabilities. In the extreme cases imagine a corpus of literature solely describing elephants, and images of elephants as a highly interlinked pair of datasets, and the same literature but this time accompanied solely by pictures of soccer balls for the sparsely linked. Note they will never in practice be identical or completely unlinked, as within any medium lies some trace of the reality that it belongs to. However, the degree to which they can be useful can vary wildly.
Milestone Innovations Driving Multimodal AI:
LXMERT (Learning Cross-Modality Encoder Representations from Transformers) was a model that achieved state-of-the-art performance in 2019. LXMERT is pre-trained on a vast dataset of image-sentence pairs and learns from five tasks to understand the connections between images and text, ultimately performing at tasks like visual question answering and visual reasoning.
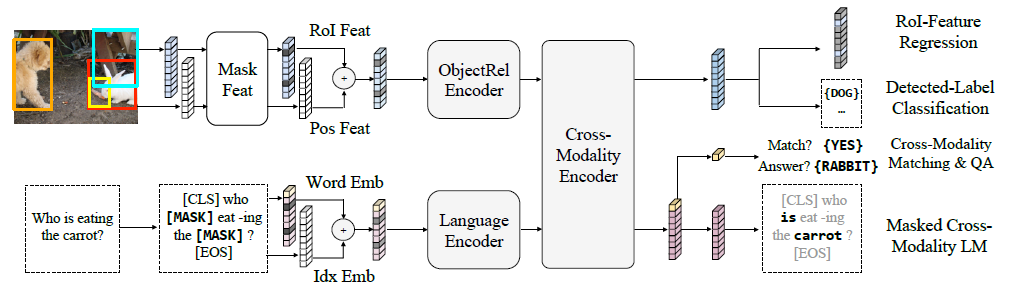
LXMERT ‘s improved performance is attributed to the masking process which allowed the dataset to be used very efficiently, isolating information commonalities within words and images and assisting in the building of intuition.
Barely a year after their previous publication, the team at OpenAi produced Learning Transferable Visual Models From Natural Language Supervision . This was the birth of CLIP (Contrastive Language-Image Pre-training) a Vision-Language-Transformer architecture that was trained on a dataset of over 400 Million image-text pairs collected from the internet.
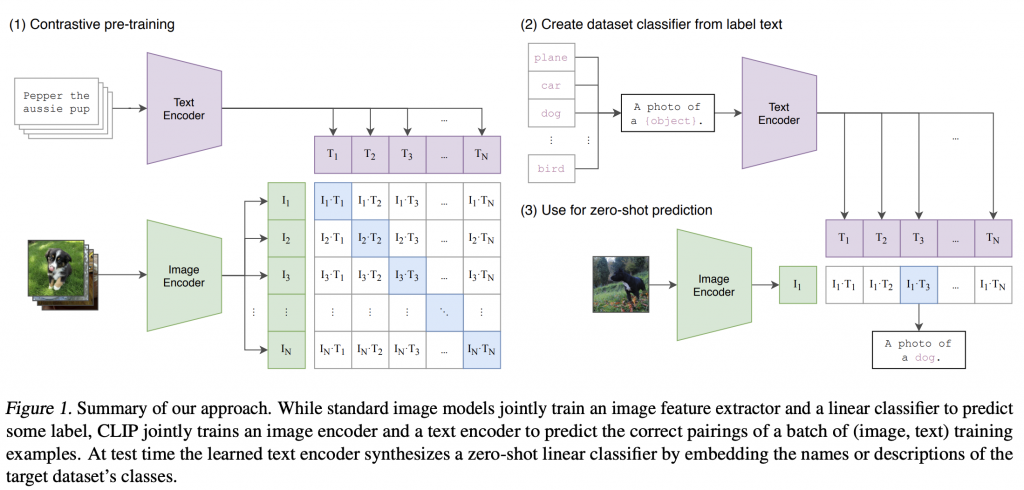
Stepping outside the box, slightly.
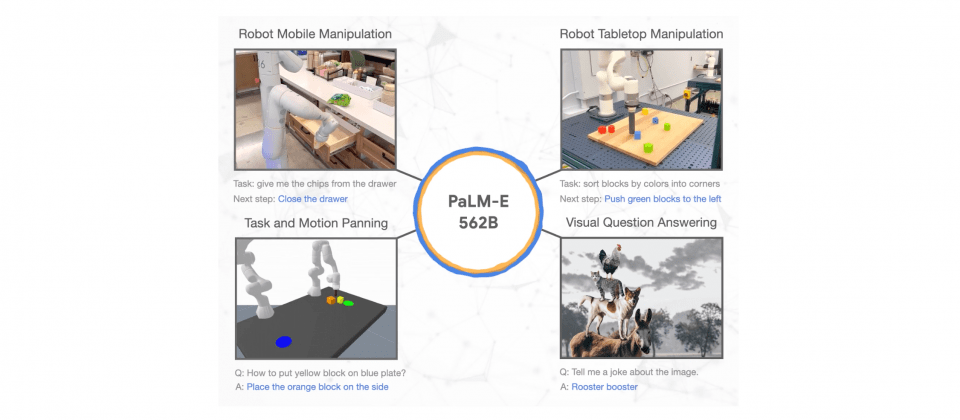
Beyond the Horizon: The Future of Multimodal AI:
If we take a small step back for a moment we can start to build some intuition around the story and how it is unfolding. We started by building highly tuned architectures that would produce good results on limited datasets and would require rigorously tuned parameters and hyperparameters to do so. Scaling was shown to provide large increases in both quality and generatability of the models and we are taking advantage by using the massive amounts of data that the internet generates. Next we realise that a singular data type, be it images, audio or text alone can never complete the entire picture and we have now started to combine increasingly more and more disparate types of data. So what’s next?
I anticipate that as foundational models become increasingly sophisticated and efficient through the incorporation of diverse data types and increasing volumes, a clear trend will emerge. Large unimodal foundational models, which will gradually refine and condense into their most optimal and compact forms, will likely evolve in two primary directions: (1) integration as modular components within a singular multimodal head or (2) assimilation into a single, expansive multimodal model that encompasses data from various sources.
Concluding Thoughts
The fun part is, in the end what happens is completely up to us. The future of multimodal models is not predetermined; it’s a canvas shaped by our choices and priorities. As we continue to advance these technologies, we must consider the ethical implications, ensuring that they are developed and deployed responsibly for the betterment of society. The journey ahead is exciting.