Pixels to Print: Using 3D Generative Models for Additive Manufacturing
When I turned 18, long before they became fashionable, I decided to build my own electric bike. More precisely, I wanted to convert my daily ride into an electrically assisted vehicle. The project was very successful until a part literally blew up while climbing a particularly steep hill. Although I had the skills to design it, getting the first prototype machined out of billet aluminum was not only a lengthy process but also resulted in subpar results and cost me more than a month’s salary. Since then, I’ve been a dedicated member of the 3D printing fanatics society. Using a 3D printer for that project would have cost me significantly less and taken a fraction of the time.
Motivation
Today, with 3D printers becoming as common as early-day microwave ovens, a new creative freedom has emerged for general tinkerers. However, sometimes this abundance of creative freedom can be overwhelming. Many 3D printers spend more time idle than their owners would likely admit. It seems the bottleneck is designing things fast enough. As an experienced engineering designer, I usually solve my problems efficiently. Helping others, though, is a different story. Requests can be far from engineering-related, such as “I want a dragon, but cuter, with longer ears, a thinner tail, and a bigger head.” For someone not trained in modeling or 3D sculpting, these requests can be frustrating.
Recently, as part of a Masters in AI course, I had a machine vision assignment to identify a use case for a model and explore the state of the art in the field. This led me to dive deep into the world of 3D generative models to see how they could help bridge the gap between ideas and tangible 3D prints.
Exploring 3D Generative Models
To tackle the challenge of translating creative ideas into 3D models efficiently, I explored several cutting-edge 3D generative models. Each model offers unique capabilities and can address different aspects of the design-to-print process. Iv tried to extract the interesting things I have found through this process and will attempt to pass them on below.
DISCLAIMER: All my opinions are a reflection of my own experience and are not meant to shed a bad light on anyone or any company behind these models. Also all of the timing related comments come from running on a 13900k with 128Gb Ram and a 4090 GPU, you will of course experience better or worse performance if you are using different hardware.
Shap-E
Shap-E is a transformer-based model that takes text descriptions and turns them into 3D objects. Unlike older methods, Shap-E uses implicit functions—fancy math tools to represent object shapes—which gives it more flexibility. Some examples are Signed Distance Functions and Occupancy Functions. Although the initial setup was tricky due to outdated instructions, I managed to get it working with some alternative libraries and ran it on a Jupyter Notebook. Shap-E is impressively fast, generating objects in just minutes, and you can customize the image size and output variations.



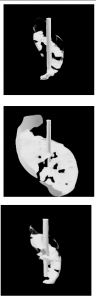
Large Reconstruction Model (LRM)
The Large Reconstruction Model, or LRM, is pretty unique because it’s fully differentiable, meaning it gets trained all at once rather than in parts. The version I used, OpenLRM, can generate 3D models from images. For direct comparison, I used images from the state-of-the-art text-to-image step. Interestingly, LRM uses Dino, a self-supervised architecture also known as a teacher-student architecture. This model creates a triplane embedding in the latent space, which then informs a NeRF model. Each iteration took a few minutes, but this is just for the image-to-3D part and can’t be directly compared to others.


Large Multi-View Gaussian Model
This model takes a different approach by using an asymmetric U-Net base model to run multi-view diffusion, creating a Gaussian splatter 3D representation of the object. The final models from this were in point cloud form.

One downside is its current inability to handle non-heterogeneous shapes well, such as seen in the example of the boat below. However it does a great job with models that have aspect ratios closer to 1.
Dream Fusion
Dream Fusion uses Imagen for the text-to-image part. It starts with a randomly initialized NeRF model and uses Score Distillation Sampling with random camera positions to guide NeRF’s training. On average, it needed about 90 minutes per object, which was a bit restrictive and led to only a few items being successfully generated. Also, maintaining it was a headache, often requiring a complete PC format and re-installation. So, further testing wasn’t feasible within the scope of this work, and I compiled results from the few available examples.



Dream Shaper and TripoSR Pipeline
This pipeline combines two models: Dream Shaper, a community-tuned stable diffusion model for generating quasi-realistic 3D models and characters, and TripoSR, a descendant of LRM with several improvements, including no need for explicit camera positioning. This combo, with some image processing in between, produced some of the best 3D objects. It was also the quickest to run, taking only a few seconds per cycle, and came built into ComfyUI, a community-driven UI for making Stable Diffusion models more accessible.






Evaluation
Since these models are implemented in different and mostly custom ways and their outputs vary, a qualitative evaluation approach was chosen. Eight prompts, each differing in significant ways (length, abstraction, practicality, etc.), were used. Standard negative prompts were employed for models that needed them. For LRM, only the image-to-3D part was implemented, using images from the state-of-the-art model for comparison.
To generate models for each of the eight prompts, 100 epochs were allowed for each model with three pre-set seeds for repeatable results. This method generated three different 3D objects per prompt, with no cherry-picking allowed.
Conclusion
Exploring 3D generative models, from Shap-E to the Dream Shaper and TripoSR pipeline, showcases the incredible progress in creating realistic and detailed 3D objects. These advancements can significantly streamline the design process, making it more accessible to those without extensive modeling skills and allowing for a more efficient transition from concept to tangible print.
Reflecting on my journey from building an electric bike to diving into 3D printing and generative models, the potential for these technologies is vast. However, there’s still much work to be done. Future research could focus on improving model robustness, expanding the variety of models that can be successful generated.
In essence, the continued evolution of 3D generative models promises a world where unbounded creativity can be more easily transformed into reality, opening new frontiers for innovation and personal expression. The journey doesn’t end here; it’s just beginning, with endless possibilities for future exploration and development.